
This blog post is written and published on Hyper-V.nu: https://hyper-v.nu/archives/bgelens/2014/08/bare-metal-post-deployment-introduction-and-scenario-part-1/
Introduction
In this series of blog posts I will describe a method for Hyper-V host Bare Metal Post-deployment which I developed and have been using in a production environment. This method of course is just one example of a viable solution and it is not per se THE method. My intention is that you can gather enough information from these posts to develop your own method.
This method uses:
- SCVMM Custom Resource containing PowerShell configuration scripts and supporting executables (a.k.a. Generic Command Execution, GCE).
- Service Management Automation (SMA) runbooks to orchestrate the post installation process and parallelize the process across multiple hosts.
When this blog post series is done, the entire post deployment sequence can be fully automated and made available at the push of ONE button!

When I just started working with the bare metal deployment features of SCVMM 2012, I soon found this blog written by Mike DeLuca. My work started based on this blog post so many credits go here!
These blog posts are not intended to be a PowerShell or SMA course. I will assume you are able to read and interpret the PowerShell lines provided and will not go into detail what every line does. Instead I’ll briefly describe what happens when a script or runbook is executed.
This blog post series consists of 5 parts:
- Part 1: Introduction and Scenario
- Part 2: Pre-Conditions (this blog post)
- Part 3: Constructing the Post-Deployment automation
- Part 4: Constructing the Post-Deployment automation continued
- Part 5: Running the Post-Deployment automation and Bonus
So that’s it for the introduction, let’s move on!
Scenario
For this blog post I have 2 environments, Production and Test, with the same hardware (HP BL460c Gen8). Servers have been bare metal deployed with Windows Server 2012 R2.
All blades are equipped with 2 Emulex FlexibleLOMs I/O cards (2x 40Gb/s full duplex). Let’s elaborate a little bit so you have a better understanding (what I explain here is the 554 family of FlexibleLOM cards, other cards can have different options).
A FlexibleLOM I/O card can be divided into multiple FlexNICs and a FlexHBA (Host Bus Adapter). FlexibleLOM cards have 2 ports each mapped to a respective interconnect bay port (FlexFabric or Flex10). The cards can have a maximum of 4 devices per port (3 FlexNICs and 1 FlexHBA per port). The FlexHBA can be either an FCOE or an iSCSI HBA. In this case the FLB card (FlexibleLOM for Blade, mandatory card installed at manufacturing) will have 1 FCOE FlexHBA per port to facilitate FCOE connectivity for the CSV and Quorum volumes and virtual Fibre Channel Switches (2Gbps per port is still unassigned which can be used for other means, e.g. iSCSI VM switches). The Mezzanine card will have 2 FlexNICs, 1 for infrastructure connectivity per port and 1 for VM connectivity per port. Bandwidth for all FlexNICs and FlexHBAs is assigned with minimum guaranteed values but is allowed full capacity when this is available and required. At the Windows level, all NICs are 10Gbps which is a behavioral change introduced in Virtual Connect firmware 4.01 (at firmware levels before 4.01 the bandwidth was assigned statically as a maximum value and was reported to Windows as well).
Windows is presented with 10Gbps adapters. Because of this VMQ is enabled the moment a VM Switch is attached to an adapter.
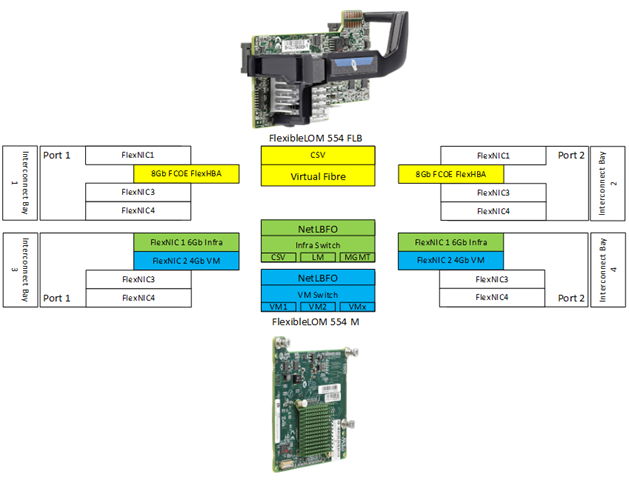
Because port 1 and port 2 of each adapter breaks out to a different interconnect bay which on their turn break out to a different core switch and / or Fibre fabric, full path redundancy can be achieved by teaming the FlexNICs at the OS level and by using MPIO for the Fibre connections.
Fully converged networking will be implemented by the post-deployment process (to work around the SCVMM MAC address issue I blogged about earlier) which means the hosts have been deployed with a physical NIC assigned as the management NIC.
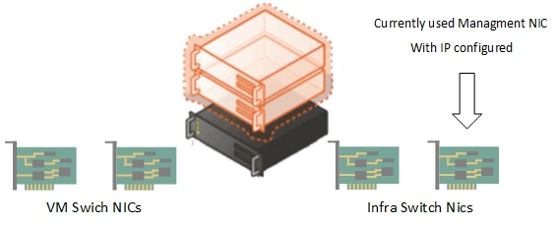
A logical switch still has to be implemented to host the vNICs for management, csv and live migration (from now on called the Infra Switch) and the physical NIC used for initial management communication will be part of the team. Another 2 NICs will be used for a logical switch used for VM connectivity (from now on called VM switch).
Both switches will be configured as switch independent teams with dynamic as the load balancing algorithm.
Side note
I know this configuration is not on par with what you have been reading on many blogs because of the “performance penalty” induced by the use of VMQ on the management OS vNICs. The CPU core assigned to the Queue forms the processing bottleneck which is why you cannot reach more than approximately 5,4Gbps. I can tell you from experience and a lot of testing that I do NOT see these penalties actually to exist. At least not as dramatically as commonly described. In my environment I am perfectly able to Live Migrate with nearly the full 10Gbps potential over a vNIC with VMQ enabled. 20Gbps when simultaneously migrating in and out. I’ve verified my results with other environments and Marc van Eijk also tested from a VM’s perspective with results better than he expected after I discussed my findings with him. My only hope now is that Microsoft will introduce vRSS for management OS vNICs in vNEXT so I can spread the CPU cycles across multiple cores resulting in a better balanced system. If you would like to know more about my experiences or if you want to discuss your own experiences about this subject, please feel free to contact me.
The bare metal post-deployment process for each environment (production and test) will differ in uplink port profiles used by the VM Switch.
In this case Emulex I/O cards are used and will be utilized with Fibre Channel over Ethernet (FCoE) host bus adapters (HBAs). N-Port ID Virtualization (NPIV) must be enabled as part of the deployment process to allow the HBAs to be used with virtual fibre channel switches. The virtual fibre channel switches will be implemented as part of this solution as well.
Additionally, the VMQ indirection table will be configured with some other advanced NIC settings like Jumbo frames.
A sort of network startup order exist when fully converged networking is used. When a host powers on the following network devices are brought online sequentially:
- Physical NICs
- NetLBFO Multiplexor NIC
- vNIC
For every step in this sequence, the TCP/IP stack and configuration of that NIC becomes active, which can result in DHCP leases and dynamic DNS updates you do not want! As part of the process we will implement a fix for this behavior.
There are many more tasks which could be executed (e.g. install SCOM and SCCM agent), but remember I compiled this blog to give you some handles on how to utilize this method, not to give you an end-to-end solution.
That’s it for the first blog post. Hope you have got a clear view on what we are trying to achieve here and why we want to automate this all. Just imagine doing all this all by hand for 16, 32, 128 or more blades with identical setups. The margin of manual introduced errors is just too great, not to mention the lost man hours which could be spend on other tasks. Also when you have this automation in place, you can expand it to fully automate re-deployment as well. No need to repair your host, just evacuate all running workloads from it and push a button!